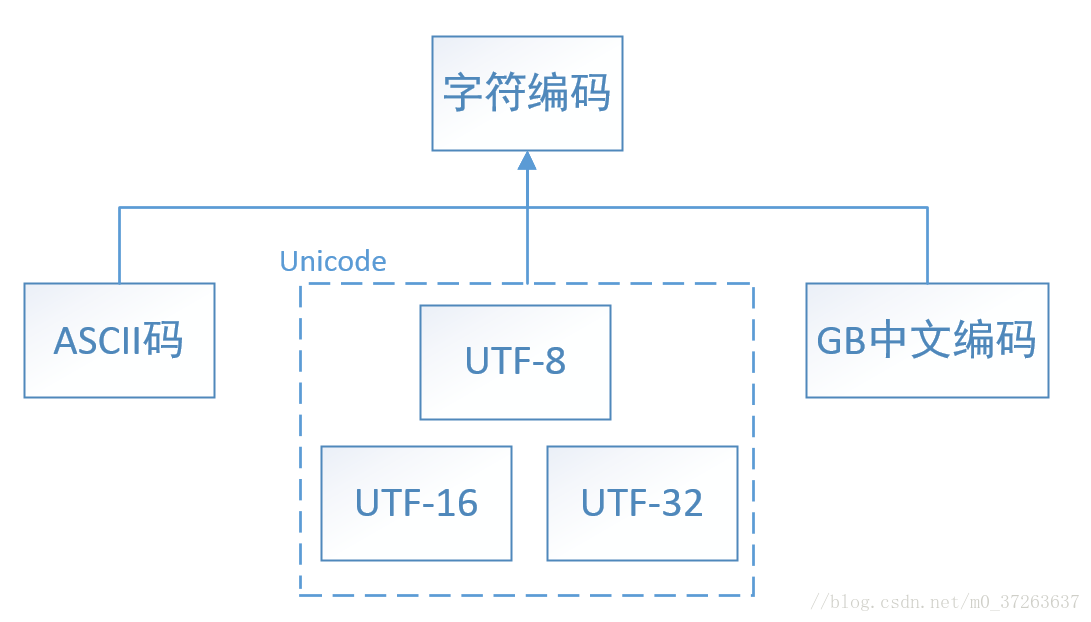
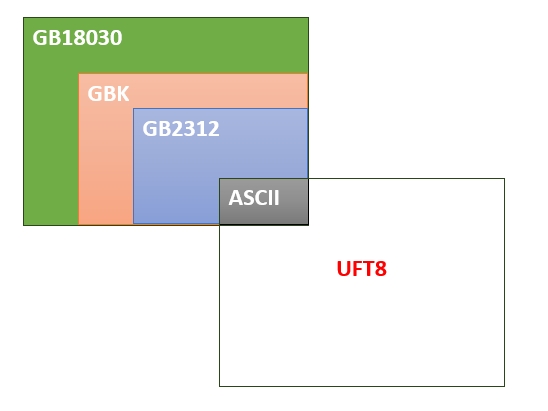
Unicode字符集
为了解决不同国家ANSI编码的冲突问题,Unicode应运而生:如果全世界每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。
Unicode 是一套字符集,而不是一套字符编码
任何文字在Unicode中都对应一个值, 这个值称为代码点(code point)。代码点的值通常写成 U+ABCD 的格式。 而文字和代码点之间的对应关系就是UCS-2(Universal Character Set coded in 2 octets)。 顾名思义,UCS-2是用两个字节来表示代码点,其取值范围为 U+0000~U+FFFF。
为了能表示更多的文字,人们又提出了UCS-4,即用四个字节表示代码点。 它的范围为 U+00000000~U+7FFFFFFF,其中 U+00000000~U+0000FFFF和UCS-2是一样的。
Unicode字符集支持三种字符编码方式:UTF-32,UTF-16,和UTF-8。
UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
最好用的是UTF-8编码,只有 UTF-8 兼容 ASCII,UTF-32 和 UTF-16 都不兼容 ASCII,因为它们没有单字节编码。
完整的 Unicode 字符集,以及各种编码方式:在这里:https://unicode-table.com/cn/
UTF存储大小端的问题:
BOM即Byte Order Mark字节序标记。BOM是为UTF-16和UTF-32准备的,用户标记字节序(byte order)。拿UTF-16来举例,其是以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流"594E",那么这是“奎”还是“乙”?
小端字节序简写为 LE( Little-Endian ), 表示低位字节在前,高位字节在后, 高位字节保存在内存的高地址端,而低位字节保存在内存的低地址端
大端字节序简写为 BE( Big-Endian ), 表示 高位字节在前,低位字节在后,高位字节保存在内存的低地址端,低位字节保存在在内存的高地址端
Unicode规范中推荐的标记字节顺序的方法是BOM:在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"(零宽度无间断空间)的字符,它的编码是FEFF。而FEFF在UCS中是不不能再的字符(即不可见),所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者接收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称为BOM。?
UTF-8是以字节为编码单元,没有字节序的问题。UTF-8 BOM又叫UTF-8 签名,UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。当文本程序读取到以 EF BB BF开头的字节流时,就知道这是UTF-8编码了。Windows就是使用BOM来标记文本文件的编码方式的。